Unlocking the Secrets of Multimodal Models: How Word Co-occurrence Dictates Performance
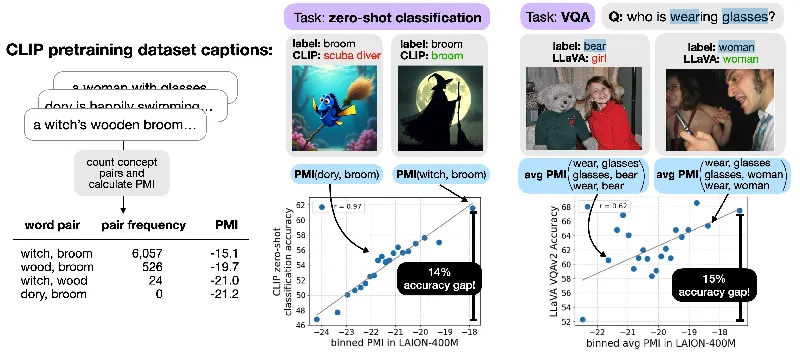
Recent research sheds light on a pivotal aspect of how large multimodal models (LMMs) perform, specifically focusing on the role of word co-occurrence in their training data. In a collaborative study by Helen Qu of the Flatiron Institute and Sang Michael Xie from Stanford University, the researchers explore how the frequency of word pairs influences the accuracy of models like CLIP across various visual tasks.
The Importance of Co-occurrence
CLIP (Contrastive Language-Image Pretraining) excels at associating images with text, but its performance drastically varies based on how often different concepts appear together in training data. Surprisingly, the study finds that even common objects get misclassified when they appear with less familiar counterparts. For example, the correlation between the frequency of concept pairs in the training data and CLIP's accuracy was shown to be extremely strong—up to 97%—indicating that the combination of objects in an image can heavily influence how accurately a model identifies them.
Unveiling the Findings with Synthetic Data
To unravel this relationship, the researchers created synthetic datasets featuring pairs of concepts with different levels of co-occurrence as measured by pointwise mutual information (PMI). The results were staggering, revealing up to a 14% accuracy drop when concepts with low co-occurrence were used. This statistic showcases that not just the individual concepts, but their relationships matter deeply in training these models.
From Synthetic to Real: The Transfer of Insights
The study didn't stop with synthetic images; it also focused on natural ones. By editing real images to introduce manipulated co-occurrence rates, they verified that their findings held true even in more authentic scenarios. In these tests, when images were altered to include pairs of concepts with a low PMI, the models struggled even more, showing a 10% accuracy decline. This reinforces the idea that the models are heavily biased by the statistical landscapes of their training data.
Significance for Future AI Development
This research underscores a significant challenge for AI development: current models tend to learn from the data they are trained on but fail to generalize well to new combinations of concepts they have not encountered. The findings signal a need for more sophisticated algorithms capable of understanding concepts and their relationships better, rather than merely expanding training datasets economically.
The Next Steps
Moving forward, the researchers advocate for new architectures and methods that could strengthen the compositional generalization capabilities of multimodal models. By navigating the complexity introduced by co-occurring concepts, developers could build AI systems that are not only more effective in performance but also more reliable in their predictions across diverse scenarios.
With open-source code available for further exploration, this study represents a crucial step in refining our understanding of how LMMs interpret the real world through the lens of language and vision.

