Transforming Medical AI: Introducing MedThink-Bench for Expert-Level Evaluation of Language Models
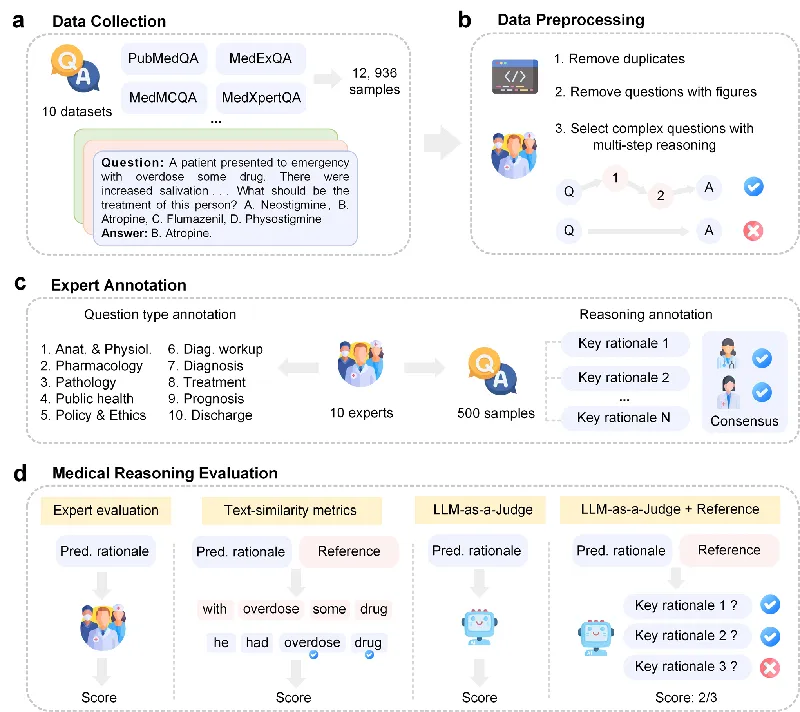
As artificial intelligence continues to advance, the integration of large language models (LLMs) into healthcare has reached a pivotal moment. A groundbreaking study led by Shuang Zhou and colleagues presents MedThink-Bench, an innovative benchmarking tool designed to rigorously evaluate the medical reasoning capabilities of LLMs. This development holds remarkable implications for ensuring that AI systems provide reliable and transparent support in clinical decision-making.
The Challenge of Medical Reasoning in AI
Despite the impressive capabilities demonstrated by LLMs in various medical tasks—such as diagnosing diseases and planning treatments—their deployment in high-stakes environments has been met with skepticism. A fundamental issue lies in the often opaque reasoning processes of these models, which can lead to outputs that are not only incorrect but also lack the transparent support needed for clinical validation. As a result, integrating LLMs into healthcare demands a robust evaluation method that transcends simple accuracy checks.
Unveiling MedThink-Bench
To address the inadequacies in current evaluation strategies, the researchers have introduced MedThink-Bench, a dataset comprising 500 carefully curated medical questions spanning ten diverse domains—including Pathology, Anatomy, and Public Health. Each question is equipped with expert-annotated step-by-step rationales, effectively mirroring the detailed reasoning expected in actual clinical settings. This innovative benchmarking tool sets the foundation for reliably assessing the reasoning quality of LLMs against expert judgments.
LLM-w-Ref: A Novel Evaluation Framework
Alongside MedThink-Bench, the researchers developed LLM-w-Ref, an evaluation framework that refines the assessment process by utilizing fine-grained rationales and employing LLMs as evaluators. This allows for more sophisticated analysis of intermediate reasoning phases, leading to outcomes that align closely with expert opinions. In experimental comparisons, LLM-w-Ref exhibited a strong positive correlation with human expert evaluations, demonstrating its potential to enhance the credibility and utility of AI in medicine.
Unexpected Findings: Smaller Models Outperforming Larger Ones
A surprising revelation from the study was that smaller models, such as MedGemma-27B, demonstrated superior medical reasoning capabilities compared to larger proprietary models like OpenAI-o3. This finding underscores that size alone does not determine performance; rather, it highlights how tailored training and evaluation frameworks can unlock the full potential of smaller models in medical reasoning tasks.
Implications for Future Clinical Practice
With the introduction of MedThink-Bench and LLM-w-Ref, this research not only provides a comprehensive framework for evaluating the reasoning of LLMs but also advances the dialogue about their responsible integration into clinical practices. By addressing previous evaluation shortcomings and emphasizing the importance of transparent, explainable reasoning, these tools pave the way for safer AI applications in healthcare, fostering trust among medical professionals and patients alike.
In conclusion, the implementation of rigorous benchmarking tools such as MedThink-Bench represents a significant step towards ensuring the reliability and effectiveness of AI in medical domains. As we move forward, fostering a deeper understanding of how these models reason will be crucial for their successful deployment in our healthcare systems.

