
Supercharging AI Agents: How UltraQuant's 4-Bit Caching is a Game Changer for Efficiency
In a groundbreaking study, researchers from Advanced Micro Devices (AMD) and top universities have introduced UltraQuant, an innovative approach to 4-bit key-value (KV) caching that aims to enhance the performance of context-heavy AI agents significantly. This advancement is crucial as AI models evolve, requiring more efficient methods to manage vast amounts of data while ensuring fast response times.
The Challenge of Context-Heavy Agents
Today's large language models and AI systems are expected to perform tasks across lengthy conversations and extensive data contexts, leading to hefty demands on memory and efficiency. As agents attempt to retain and recall important information over multi-turn interactions, the struggle to keep vital data in cache while balancing performance becomes critical.
UltraQuant specifically addresses these challenges by presenting a scalable 4-bit KV cache that enhances memory efficiency without compromising the quality of responses. This is especially pertinent as AI models grow, with capabilities to handle context windows that approach a million tokens.
Pioneering Performance Through 4-Bit Caching
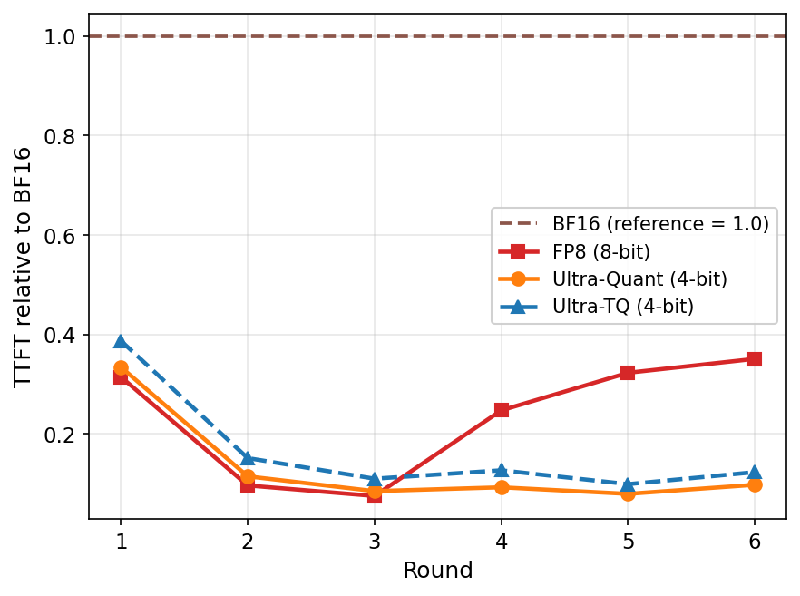
The research team’s unique approach to 4-bit KV caching introduces a compression method that drastically reduces memory overhead while maintaining response quality, a feat achieved through clever system optimizations. With UltraQuant, the researchers reported a staggering improvement in key metrics: it cuts the time-to-first-token by 3.47 times in memory-stressed situations and boosts output throughput by 1.63 times over previous benchmarks.
This is particularly significant for environments where AI agents engage in complex tasks akin to those found in software engineering, web browsing, and tool usage, as it improves their responsiveness and efficiency in real-time scenarios.
Technical Innovations Underlying UltraQuant
UltraQuant employs state-of-the-art techniques like TurboQuant-style rotation and fixed point approximations, effectively creating a compact representation of data that can be processed efficiently. Users will appreciate how these adjustments lead to less reliance on high-bandwidth memory, which has been a bottleneck in previous iterations of AI models. By integrating hardware-native instructions, the system also aligns closely with AMD's GPU architecture, ensuring high performance with reduced overhead.
The interplay between compression, data residency, and serving throughput means that UltraQuant not only pushes the boundaries of AI performance but also sets the stage for further advances in the field of efficient computing. This is vital for deploying large-scale models in resource-constrained environments.
A Future of Smart, Efficient AI Systems
The implications of the UltraQuant study extend beyond mere performance improvements. By enabling AI models to handle longer contexts more effectively, it facilitates a wider range of applications, paving the way for smarter, more interactive AI systems. As AI continues to integrate into various sectors, such advancements signal a robust future where machines can communicate seamlessly with humans, retaining context over extended engagements.
With further research and development, UltraQuant could redefine practices across industries, making it an essential area of focus for anyone interested in the future of AI and data-intensive applications.
Authors
Inesh Chakrabarti, David Limpus, Aditi Ghai Rana, Bowen Bao, Spandan Tiwari, Thiago Crepaldi, Ashish Sirasao. Affiliated with Advanced Micro Devices and several leading universities.





