
Multi-LCB: The Game-Changer for Evaluating Code Generation Across Programming Languages
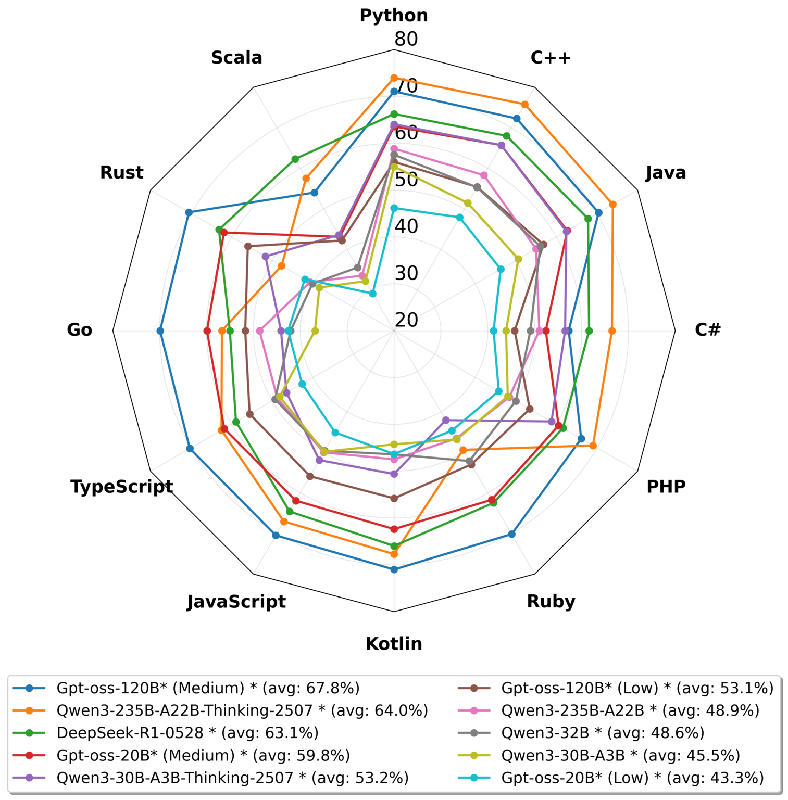
In an era where large language models (LLMs) are redefining the boundaries of code generation capabilities, a significant new development has emerged—Multi-LCB. This research introduces a comprehensive benchmark for assessing LLMs not just in one programming language, but across twelve diverse languages. With this benchmark, developers and researchers can now identify and address the limitations of existing models, particularly when it comes to generating quality code in languages beyond Python.
Extending the Benchmarking Landscape
Previously, the well-regarded LiveCodeBench (LCB) only evaluated models based on their Python programming capabilities. While Python is widely used, it does not reflect the full spectrum of challenges developers face in real-world software engineering, where multiple languages are commonly employed. With Multi-LCB, the researchers have taken the original framework of LCB and expanded it to include languages such as C++, Java, JavaScript, Go, Ruby, and more. This extension allows for a more holistic view of a model's coding capabilities, testing how well they can adapt across languages.
The Structure of Multi-LCB
Multi-LCB retains critical elements of the original benchmark, such as contamination-aware evaluation, which ensures that models are tested on tasks they have not seen before. This is crucial for accurate assessment, as prior training on similar problems can skew results. Each task within Multi-LCB mirrors those from LCB but presents them in a format applicable to other programming languages. This not only promotes fair evaluation but also systematically tracks progress as language models evolve.
Key Findings: The Performance Disparities Uncovered
Upon evaluating 24 different LLMs, the researchers discovered profound disparities in performance across programming languages. For instance, models that performed exceptionally well in Python frequently saw their advantages diminish when tasked with code generation in C++ or Java. This reveals a phenomenon known as "Python overfitting," where models excel in Python due to their extensive training on that language, but struggle to generalize to others.
Additionally, the evaluation highlighted the presence of language-specific contamination, where knowledge from one language negatively impacts performance in another. This means that models which simulate strong coding skills in Python may have significant drawbacks when generating code in less prevalent or statically-typed languages.
Implications for the Future of Coding Models
By opening the door to multilingual evaluations, Multi-LCB sets the stage for future innovations in programming language models. This research not only exposes the limitations of current models but also underscores the need for improvements in their training datasets. The possibility of bridging gaps in model performance across various languages could lead to the development of more robust and language-agnostic coding solutions.
With its systematic approach and commitment to rigorous evaluation, Multi-LCB promises to be a valuable resource for the community engaged in furthering research in code generation and LLM applications. As the field continues to evolve, models evaluated through this benchmark may very well lead to the next generation of efficient and capable AI-assisted coding tools.
Authors: Maria Ivanova, Pavel Zadorozhny, Rodion Levichev, Ivan Petrov, Pavel Adamenko, Ivan Lopatin, Alexey Kutalev, Dmitrii Babaev





