EXPO: The Breakthrough in Reinforcement Learning for Teaching Robots New Tricks
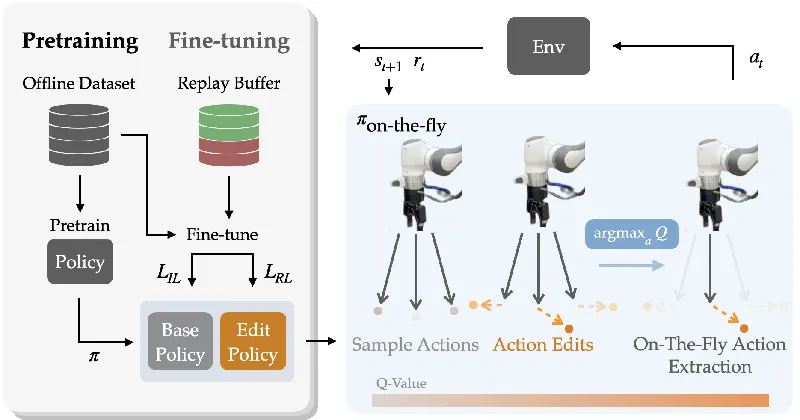
In a groundbreaking study from Stanford University and UC Berkeley, researchers have unveiled an innovative approach to teaching robots using online reinforcement learning (RL) with expressive policies. The new method, called Expressive Policy Optimization (EXPO), surmounts previous limitations in sample efficiency and stability that have hindered RL's practical applications in real-world robotic tasks.
Understanding the Challenges
Traditionally, reinforcement learning has relied heavily on simpler Gaussian policies, which lack the capability to leverage expressive policies—like diffusion or flow-matching policies—that can better mimic complex behaviors. While conventional methods showed promise, they fell short of delivering the consistent performance needed for robots to operate reliably in unpredictable environments. The EXPO framework takes a novel leap by enabling the utilization of these expressive models through a combination of imitation learning and online fine-tuning.
The EXPO Methodology
At the heart of EXPO lies a two-pronged approach that includes a larger expressive base policy, which is initially trained offline through imitation learning, and a lightweight Gaussian edit policy. This edit policy refines the actions sampled from the base policy to optimize the robot's decision-making in real-time. Instead of directly optimizing for rewards using the base policy—which can lead to instability—EXPO constructs what it terms an "on-the-fly" policy. This approach maximizes the Q-value (the expected future rewards) through a careful balancing act, choosing the best actions derived from both the original and edited outputs.
A Game-Changer for Sample Efficiency
The results from EXPO indicate a significant enhancement in sample efficiency—yielding up to 2-3 times better performance compared to existing methods. This newfound efficiency is critical when fine-tuning robots for complex tasks such as robotic manipulation or navigating intricate environments. Evaluations across 12 challenging tasks revealed that EXPO consistently outperformed other state-of-the-art methods, demonstrating its versatility and robustness across diverse domains.
Real-World Applications
The implications of this research for robotics are profound. With enhanced learning capabilities, robots can learn from fewer interactions, enabling rapid adaptation to dynamic scenarios. As robots become more proficient in their environment thanks to techniques like EXPO, the potential for their application in areas such as healthcare, manufacturing, and service sectors expands drastically. The study also reinforces the importance of expressive policies in advancing machine learning and AI's capabilities.
Final Thoughts
EXPO represents a pivotal advancement in reinforcement learning techniques, delivering a more effective method for training expressive policies. By creatively circumventing the limitations of previous models, it opens up new horizons for the development of intelligent systems capable of complex, real-time decision-making. As researchers continue to refine these algorithms, the future of robotics looks more intelligent and adaptable than ever.

