Breaking Boundaries in Image Reconstruction: The Game-Changing MGVQ Method
As artificial intelligence continues to advance, researchers are constantly seeking ways to enhance image reconstruction quality, which is vital for applications ranging from medical imaging to autonomous vehicles. A recent breakthrough brought forth by Mingkai Jia and his team proposes a new method called MGVQ, which significantly narrows the performance gap between traditional Variational Autoencoders (VAEs) and their vector quantized counterparts (VQ-VAEs).
The Power of Vector Quantization
Vector Quantization (VQ) is a crucial technique in compressing visual data, transforming complex images into manageable tokens. However, typical VQ-VAEs have struggled with information loss, leading to reconstruction errors that are far from ideal. Traditional methods often face challenges like codebook collapse—where important data points go unused—making it difficult for these models to achieve high-fidelity outputs.
Introducing MGVQ: A New Paradigm
MGVQ stands out by enhancing the representation capability of discrete codebooks. Unlike previous strategies that reduced dimensionality to avoid codebook collapse, MGVQ maintains a larger latent dimension. This means it can preserve more essential features of the original image while employing a novel sub-codebook system that enhances optimization and reduces information loss.
Empirical Evidence of Superiority
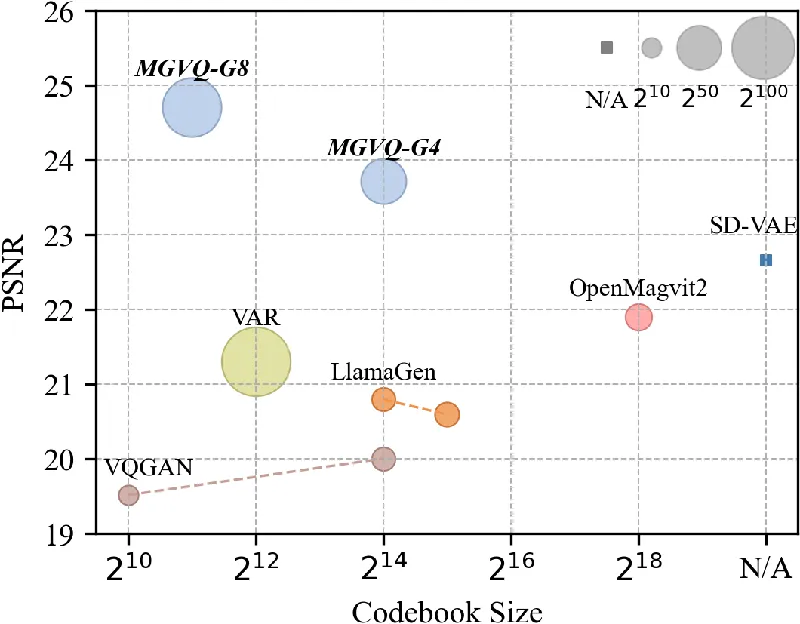
Through rigorous testing on datasets like ImageNet and various zero-shot benchmarks, MGVQ has achieved state-of-the-art performance, outperforming prominent models like SD-VAE. Notably, in one evaluation, MGVQ recorded a reconstruction fidelity score (rFID) of 0.49, a stark improvement compared to SD-VAE's score of 0.91.
Key Contributions of MGVQ
- Sub-Codebook Innovation: MGVQ employs multiple sub-codebooks, allowing for better distribution of token representations and easier optimization.
- Enhanced Representation Capacity: By keeping the latent dimension intact and using a group of sub-codebooks, MGVQ boosts representation capacity significantly—up to a billion-fold—in comparison to traditional methods.
- Comprehensive Evaluation Framework: A meticulously constructed zero-shot benchmark system supports the robustness of MGVQ's performance across various resolutions, allowing for a well-rounded assessment of its capabilities.
Looking Forward
The implications of MGVQ are profound for future research in image processing, suggesting that enhancing the representation capacity without compromising information can lead to higher quality reconstructions. As this technology matures, it opens avenues for applications in high-definition image rendering, medical diagnostics, and much more, pushing the boundaries of what AI can achieve in visual data interpretation.

